監督視点の野球ゲーム Meisyo+でデータが貯まってきたので、打率の予測をしてみました。
打率は高ければ高いほどいいですが、実際のところどの能力値を重要視していいかわかりません。
そのため、今回はどの能力値を重要視すれば、打率の向上によさそうかの判断基準を作りたいと思います。
使用データについては、ゲーム内の機能の分析室にデータ出力機能がありますので、そちらのデータと下記のコードを使うことで自分のチームの傾向を分析できるようにしています。
実験方法
コードの詳細については、Github:meisyo_analysis/ver1をご覧ください
使用データ
・選手の属性
・選手の能力値
・選手の打撃結果(集計値)
使用データの前提
野球は投手vs打者で打撃結果(打率含む)が決定しており、打者と投手の相性は少なからず存在します。(ように作ってます)
ただ今回は、選手の打撃結果が集計値のため、投手起因の値は丸め込まれていて予測できません。
つまり、野球でよく言われる「いい投手に対してかなりの打席数があったので、この打者の打率は低かった」や「この投手のカーブにこの打者は弱い」、「2ストライクになるとミートが下がるので打率が下がる」などは無視されています。
下記の結果は全体の傾向でしかない点にご注意ください。
使用データの対象
いつ?
2021/10/24現在の情報
どのチーム?
集計対象チームは、管理者(れい)のチームとNPCチームのみ。
どの球場?
全球場。
グランドの大きさ・フェンスの高さに違いがあるので、球場別に分析した方がいい気がする…。
何のデータをもとに?
選手の打撃に関わる属性値、能力値(合計値)
何を予測?
打率(回帰分析)
各種打撃結果の集計値はあるので、他の指標(OPSやWARなど)の分析は可能です。
※変数名が分からない場合はコメントください。テーブル定義書を作成します。
結果
示唆1:全体傾向
SHAPを利用して分析しています。
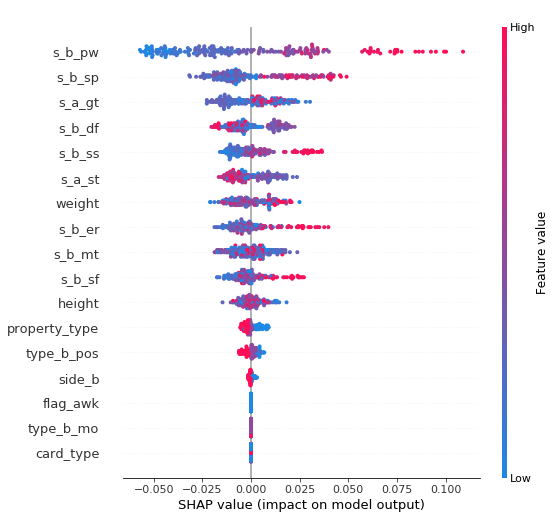
図の見方は、赤くなるほど打率が高く(青くなるほど低く)、右に行くほど変数の値も大きいです。
そのため、各説明変数がどのように目的変数に寄与しているか確認することができます。
効果がありそう:
パワー(b_pw)、走力(b_sp)、反応(b_ss)、エラー回避(b_er)
→ 当たり前の結果。
属性(property_type)、打席位置(type_b_pos)、打席(side_b)
→ 意味のある数字が出ているように見えるが、よくわからないので個別に確認する。マイナスの効果がありそう:
体力(a_st)、守備(b_df)、
→ このステータスを重視すると、選手ごとの能力値の合計を一定にしているため、打率の向上に効果があるステータスが低下するためだと考えられる。効果がなさそう:
根性(a_gt)、体重(weight)、身長(height)、肩力(b_sf)
→ 直接関係するところではない。
ミート(b_mt)
→ 驚くところかもしれないが、ゲームの進捗として変化量が多い投手が少ないのでまだ出番ではない。変動なし:
覚醒有無(flag_awk)、打撃モーション(type_b_mo)、選手タイプ(card_type)
→ 打撃モーションは設定しているものの、未実装のため。
示唆2:個別傾向
詳細は上記Githubの分析コードファイルでご覧ください。
属性(property_type):
心(H)技(T)体(B)のうち、なぜか体が有利。
投手に有利属性の心(H)が多いからか?(データはない)打席(side_b):
左打席の方が一塁に近いため、ほんのちょっと出塁しやすい。打席位置(type_b_pos):
前(F)中央(C)後ろ(R)のうち、なぜかCが有利。
後ろは速球に対して反応しやすいが、変化球に弱くなりがち。→速球投手が居ないので、今のところ出番がない。
前は速球に弱いが、変化途中を打つので大きな変化球に対応しやすい。→大きな変化球を持つ投手がほぼいない。
なるほど・・・その結果、中庸の中央が強いのか。身長・体重:
まだ試合に反映していません・・・。
まとめ
意外や意外、打率にはミートがほとんど寄与していない傾向にあることがわかりました。
今のところパワー is 力になっていますが、投手が育ってくると速球・変化球のどちらか、またはどちらもに対応する必要が出てくるため、ミート(変化球)と反応(速球)が必要になってきます。
ただし、打撃ばかりに注力していると守備特化や走塁特化にボロボロにされる現象が出てきます…。
NPC早波高校が良い例だと思います。あいつらは強い。
どちらかというと現状は守備を優遇した計算にしているつもりですが、バランスが悪い場合はバランス調整が入る可能性があります。
それでは、また~(^^ノ
Appendix
Light GBM sample_weightの有効性確認
有効性があると考えられる結果となりました。
詳細は上記Githubの分析コードファイルでご覧ください。
コードの記法
# btr_pa(打数:重み)を取得する
X_train_weight = X_train['btr_pa']
X_train = X_train.drop(columns=['btr_pa'], axis=1)
X_valid = X_valid.drop(labels=['btr_pa']) # X_validがSeriesのため、dropの記法が独特
# lgb
lgb_train = lgb.Dataset(X_train, y_train, weight=X_train_weight)
lgb_valid = lgb.Dataset(X_valid, y_valid)
# model
model = lgb.train(params, lgb_train, num_boost_round=num_round)
weight=X_train_weightだけでいいのか・・・うせやろ・・・。
logistic_regression等にもsample_weightは実装されています。他のモデルでも使える普遍的な考え方ということですね。
結果
dw = diff(打率と予測打率の誤差) * weight(打数)として重み付けをした誤差で、どちらのモデルの方が予測精度が良い(=誤差が小さい)のか判定した。
sample_weightなし
図は各サンプルの誤差の分布を示しています。
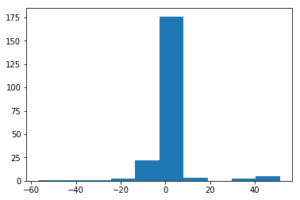
MEAN: 0.6766849656317994
MAE: 4.013002739923537
STD: 10.142118959652125
sample_weightあり
図は各サンプルの誤差の分布を示しています。
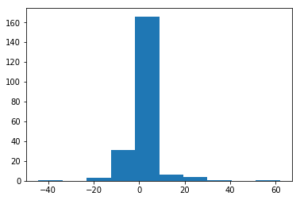
MEAN: 0.614371189810878
MAE: 3.328403506460046
STD: 7.6495407120552015
補足1
理想的にはdwは0になるといい。
ただし、そんなことはあり得ないので打数で重み付けして、打数が多い場合の誤差に罰則を大きくしている。
補足2
sample_weightの重要性は最近下記の本で目覚め、
お仕事(DX人材教育(ライフサイエンス系))で、この疾病の予測で重要視すべき患者はどの人か?などの回答に使えると思っています。使い方としてはアンダーサンプリングしない不均衡データ予測、計算方法はIPWなどとよく似ている…?似てないか。
その他のお仕事でもsample_weightを導入することで、予測精度の改善に寄与することを確認しました。
補足3
sample_weightの考え方は重要度が増してくると思うので、再度調べて記事を書きたいと思います~。
どうすれば上手く使えるかなあ。







