手書き文字の判定精度が全然上がらないので、他の手法を試してみました。
sklearnの開発元によると、以下の方法が良いらしい・・・。
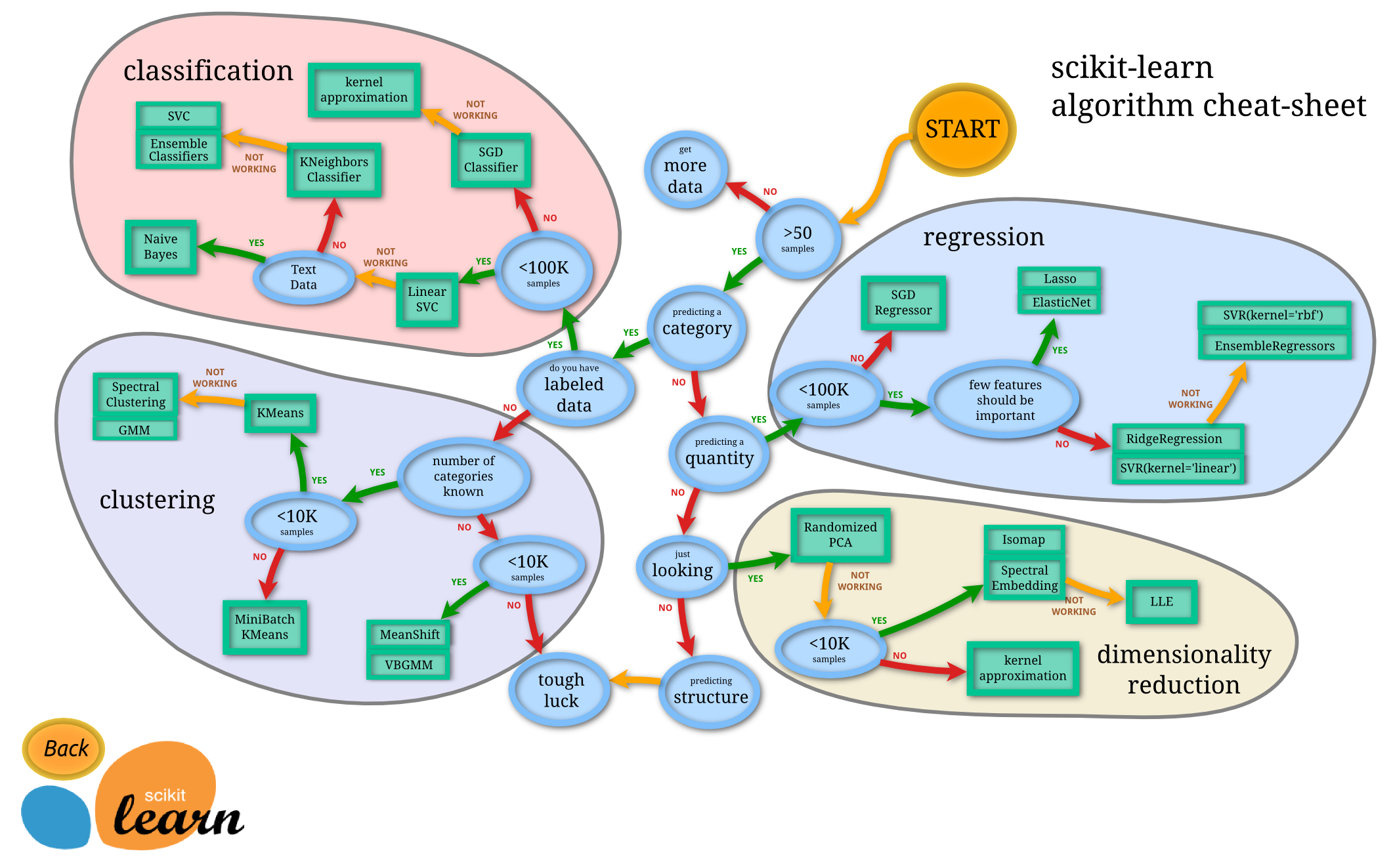
なるほど!SVCで上手くいかない → K近傍法だな!
早速実装
predict.py
from sklearn import datasets
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.externals import joblib
# データセットロード
dataset = datasets.load_digits()
#全データの最大値、全データ数確認
#print(np.amax(dataset.data)) # 最大値16
print(dataset.data.shape[0]) # 全データ数
# 設定用
x = dataset.data / 16 # 最大値を1にする
y = dataset.target
# 訓練データ/テストデータの分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=1)
# モデル作成
model = KNeighborsClassifier(n_neighbors=10)
# 学習
model.fit(x_train, y_train)
# 推定
y_pred = model.predict(x_test)
# 評価
score = metrics.accuracy_score(y_test, y_pred)
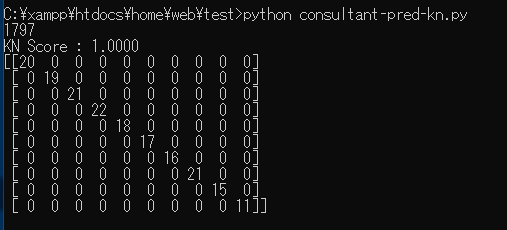
print("KN Score : {0:.4f}" . format(score))
# 間違い探し
co_mat = metrics.confusion_matrix(y_test, y_pred)
print(co_mat)
# 学習済みモデルの作成
joblib.dump(model, "consultant.pkl", compress=True)
sklearn上では・・・精度100%?
すごくいい数字です。ちなみにSVCは0.98程度でした。
結果
 ✕
✕
 ○
○
 ○
○
 ✕
✕
 ○
○
 ✕
✕
 ○
○
 ✕
✕
 ✕
✕
 ○
○
結果まとめ
正答率:5/10
・・・(^o^;)
正答率は良くはなりましたが、まだまだ未完成みたいですね。
データ整形のサイズを56×56→8×8にする時に、
mean(平均値)で丸めちゃってるのがおかしいのかな・・・。
つづく、はず。







