はじめに
筆者は仕事柄Pythonのコードレビューをすることが多いのですが、まれにPandasに行を追加する最適な方法で相談されることがあるので、今回書きました。
まず言えることは、Pandasの標準的なappendは使わない方がいいです。
では、何を使えばいいのか?ということで、今回主要な方法で実験してみました。
実験方法
2カラム(どちらもランダムな数値)を追加していく。
1万回繰り返した時に、どの方法が一番早いか平均値で比較する。
結果
比較した7つの方法のうち、比較的早い3つの方法をピックアップして処理時間の統計情報(n=1000)を取得しました。


統計的に判断した結果、最速はPandas from_dict key=’columns’でした。
次点はList Appendで、3位はPandas from_dict key=’index’でした。
各々、使いどころが違うのでご注意ください。
Pandas from_dict key=’columns’
記法が他と比べ少々独特で、列思考でプログラミングする場合はこちらが良いでしょう。実行時間のばらつきも少なく、処理が他に比べて安定して早いです。
dict_col = {'input_a': [], 'input_b': []}
for i in range(iter_num):
a = random.randint(50, 100)
b = random.randint(50, 100)
dict_col['input_a'].append(a)
dict_col['input_b'].append(b)
df = pd.DataFrame.from_dict(dict_col, orient='columns')
ただし、実務において列思考でプログラミングすることはあまりなく、コード1行で1列を指定しなければならない面倒さはあります。書く量が増えることによってバグの温床になりえるので注意が必要です。
何度も繰り返し、今後変更がない部分であれば導入してよいと思われます。
List Append
一番シンプルで書きやすく、変更しやすいです。筆者も実務でのPoC(概念検証)や、MVP(最低限の機能を実装したプロダクト)作成の際にはこちらを使っています。
list_temp = []
for i in range(iter_num):
a = random.randint(50, 100)
b = random.randint(50, 100)
list_temp.append([a, b])
df = pd.DataFrame(list_temp, columns=['input_a', 'input_b'])
ただ、計算時間が1位に比べ20%増加するため、PoC以降で採用し続けるかどうかは不明です。
Pandas from_dict key=’index’
こちらもシンプルな記法です。
dict_idx = {}
for i in range(iter_num):
a = random.randint(50, 100)
b = random.randint(50, 100)
dict_idx[i] = [a, b]
df = pd.DataFrame.from_dict(dict_idx, orient='index', columns=['input_a', 'input_b'])
ただし、index(コード中i)を定義できない場合は使用できません。データにIDが割り振れる場合は、データの意図しない複製が出ないことは評価できるポイントです。
比較した方法と実行秒数
結果詳細はhttps://github.com/R2002/Pandas-Appendをご覧ください。
1. List Append
0.028s
2. Numpy Append
0.063s
「Numpyは早い」というのは行列計算が早い。Appendは遅め。
3. Pandas Append
5.349s
純正のAppendは使うのをやめときたいですね。
4. Pandas Concat
3.368s
Concatの方がAppendより早いの何でだろう。
5. Pandas Loc
7.459s
Locで行指定すると一番遅いのね。
6. Pandas from_dict key=’index’
0.026s
7. Pandas from_dict key=’columns’
0.023s
さいごに
いろいろな手法がある中で、今回の実験条件での最速はPandas from_dict key=’columns’でした。ただし、おまけで比較した結果、カラム数が増えるとList Appendが最速です。
このように、実験して比較すること(実験計画法の利用)で、さまざまな条件下での結論を出すことが可能となります。いろいろ試してみてください!
おまけ
変更: 3カラム追加
カラムを増やして比較たが、結果的に傾向は変わらず。
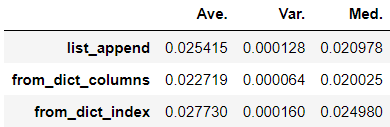
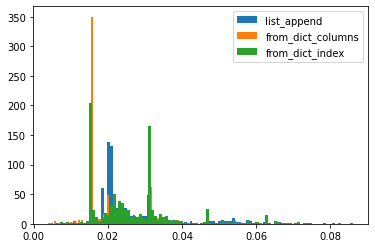
「今回は行を増やす方法を比較したが、列が増えると極端に遅くなる手法があるのではないか」という仮説でしたが、そんなに大きく変わらない可能性がありますね。
※結果は、https://github.com/R2002/Pandas-Append/blob/main/AppendTest(AddColums).ipynbを参照してください。利用環境によっても変化する可能性があります。
変更: 100カラム追加
追加で、ループ数を1万から100に変更した。
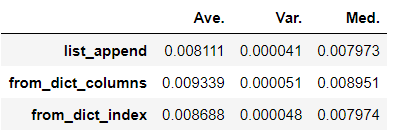
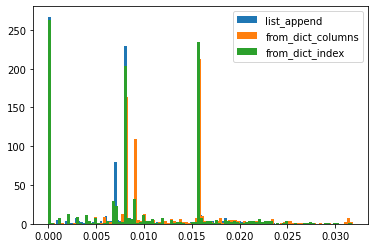
List Appendが処理速度1位になりました。つまり、ある程度カラム数が少ない場合は、Pandas from_dict key=’columns’が最速で、カラム数が多くなるとList Appendが最速になります。
※結果は、https://github.com/R2002/Pandas-Append/blob/main/AppendTest(AddColums2).ipynbを参照してください。利用環境によっても変化する可能性があります。






