ここでは、「どのパラメータが打率等にどれくらい関係するのか」を理解することで強いチームを作る指針を記載しておきます。
機械学習(重回帰分析)を使って本気で遊んでます。
実際のデータセットはこちら
野手データ 2018.12.17.csv
投手データ 2018.12.17.csv
*公平を期すために使用したデータセットを公開しています
計:146141打席
多くなりましたね。
結果
野手編
打率(AVE)、出塁率(OBP)、長打率(SLG)、OPS(OPS)
に対し・・・ミート(MT)、パワー(PW)、走力(SP)、肩力(SF)、守備力(DF)、反応速度(SS)が相関しています。
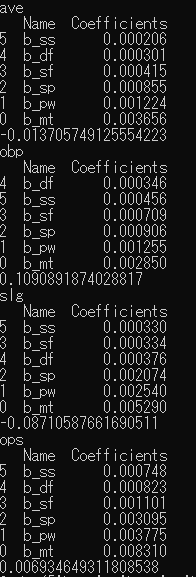
とはいえ、速球投手が全然居ないのでミート王者は変わりそうにありませんが。
昔は速球投手が猛威を奮っており、反応高くないと死ぬゲームでした。
投手編
防御率(ERA)、WHIP
に対し・・・コントロールが高ければ高いほど、ERAとWHIPは落ちる傾向。
速球とスタミナがあるとERAとWHIPが上がる・・・だと?
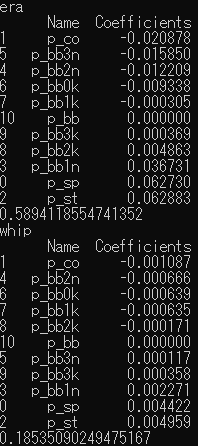
相手投手との相関性を全く考えていないデータなので、水物ではあります。日々変化しそう。
守備もデータ取ってないから説明できないのが悲しいところですね。
詳細分析
AVE
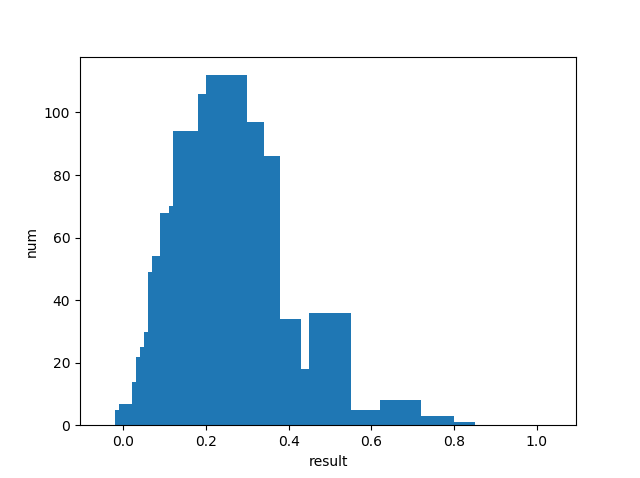
平均: 0.22
中央値: 0.22
分散: 0.01
標準偏差: 0.12
OPS
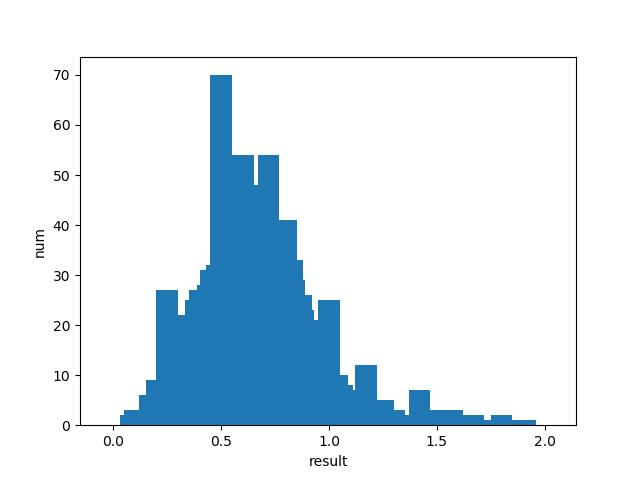
平均: 0.63
中央値: 0.64
分散: 0.08
標準偏差: 0.29
ERA(防御率)
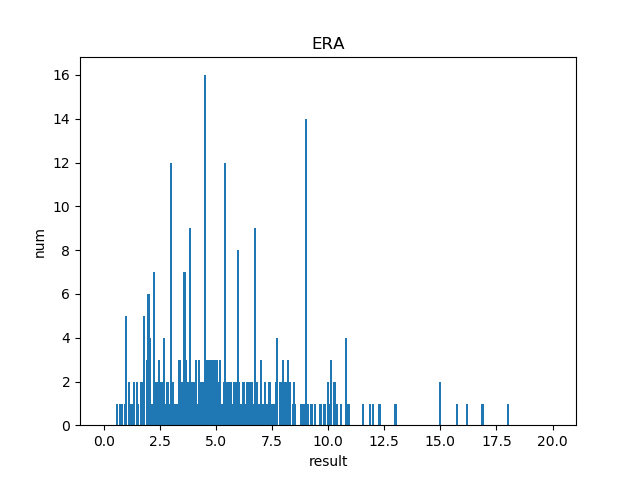
平均: 4.20
中央値: 3.91
分散: 18.28
標準偏差: 4.28
・・・こいつだけエラいばらばらやな?
WHIP

平均: 0.46
中央値: 0.50
分散: 0.09
標準偏差: 0.30
※注意:各選手の結果をリスト化して、単純に平均、中央値等を出しているだけなので、投球回数等は反映されていないデータです。ご注意ください。
分析スクリプト
コマンドプロンプトでpython他をインストールしてみてください。
グラフの出力は100行目くらいにある
sys.exit()
をコメントアウトしてくださいませ。
投手用
# -*- coding: utf-8 -*-
import os, sys, csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 基礎設定
file_name = 'meisyo_p 20181217.csv'
# CSV読み込み
df = pd.read_csv(file_name, encoding='utf-8')
# Null値を把握
# print(df.isnull().sum())
# 基礎設定
team = pd.DataFrame(index=[], columns=[])
# 投手能力結合・削除
for i in ['sp', 'co', 'st', 'bb1n', 'bb2n', 'bb3n']:
df['p_'+i] = df['p_'+i] + df['pt_p_'+i] + df['pw_p_'+i]
df = df.drop(['pt_p_'+i, 'pw_p_'+i], axis=1)
#for i in ['bb1', 'bb2', 'bb3', 'bb0k', 'bb1k', 'bb2k', 'bb3k']:
# df = df.drop(['p_'+i], axis=1)
# 野手能力結合・削除
for i in ['mt', 'pw', 'sp', 'sf', 'df', 'er', 'ss']:
df['b_'+i] = df['b_'+i] + df['pt_b_'+i] + df['pw_b_'+i]
df = df.drop(['b_'+i, 'pt_b_'+i, 'pw_b_'+i], axis=1)
team = df
# 不必要品削除
df = df.drop(['mn_id', 'name', 'side_p', 'type', 'type_p', 'hp', 'cond', 'cond_b', 'img', 'exp', 'time', 'skill', 'game.1', 'id.1', 'g_bench', 'g_pos', 'g_sb', 'game', 'pc_type', 'bt_type', 'grow_type'], axis=1)
# 欠損値のある行を削除
df = df.dropna()
# 変化球(チェンジアップ=0)ありか
df['p_bb'] = 0
if df['p_bb1'].empty or df['p_bb2'].empty or df['p_bb3'].empty:
df['p_bb'] = 1
# データセット
df = df.drop(['type_b', 'side_b', 'lv'], axis=1)
df = df.drop(['p_bb1', 'p_bb2', 'p_bb3'], axis=1)
# データ確認
#print(df.isnull().sum())
# 結果データ作成
rs = pd.DataFrame(index=[], columns=[])
rs['id'] = df['id']
rs['era'] = (df['er'] * 9) / (df['ip'] / 3)
rs['whip'] = (df['h'] + df['bb']) / (df['ip'])
# 結果削除(結果に直接相関する)
df = df.drop(['pa', 'ab', 'h', 'risp_b', 'risp_h', '1b', '2b', '3b', 'hr', 'tb', 'sh', 'sf', 'bb', 'hbp', 'so', 'e_er'], axis=1)
df = df.drop(['er', 'r', 'ip', 'wp', 'win', 'lose', 'save', 'cg', 'sho', 'gs'], axis=1)
# データ欠損値の埋め合わせ
rs = rs.fillna(0)
# データ設定
x_col = df.drop('id', axis=1)
x = x_col.values
y_era = rs.values[:, 1]
y_whip = rs.values[:, 2]
#必要なパッケージのインポート
from sklearn import linear_model
model_era = linear_model.LinearRegression()
model_whip = linear_model.LinearRegression()
# 学習する
model_era.fit(x, y_era)
model_whip.fit(x, y_whip)
# 偏回帰係数
print("era")
print(pd.DataFrame({"Name":x_col.columns, "Coefficients":model_era.coef_}).sort_values(by='Coefficients') )
print(model_era.intercept_)
print("whip")
print(pd.DataFrame({"Name":x_col.columns, "Coefficients":model_whip.coef_}).sort_values(by='Coefficients') )
print(model_whip.intercept_)
# 相関
myteam = {}
for key, row in team.iterrows():
if row['mn_id'] == 'れい' and row['type'] == 'P':
sum = 0
for i in x_col.columns:
if i is not 'p_bb':
sum += row[i]
myteam[row['name']] = '{:.0f}'.format(sum);
for k, v in sorted(myteam.items(), key=lambda x: x[1]):
print(str(k) + ": " + str(v))
# stop
sys.exit()
# グラフ用
y_eraV = ['{:.2f}'.format(n) for n in y_era]
y_whipV = ['{:.2f}'.format(n) for n in y_whip]
# plot
data = y_whipV
import collections
list = collections.Counter(data)
x = np.arange(200) / 100
values = []
for i in x:
i = '{:.2f}'.format(i)
print(str(i) + ":" + str(list[i]))
if list[i]:
values.append(list[i])
else:
values.append(0)
values[0]=0 # 0を無視
# 計算
from statistics import mean, median,variance,stdev
print(data)
data = [float(s) for s in data]
m = mean(data)
median = median(data)
variance = variance(data)
stdev = stdev(data)
print('平均: {0:.2f}'.format(m))
print('中央値: {0:.2f}'.format(median))
print('分散: {0:.2f}'.format(variance))
print('標準偏差: {0:.2f}'.format(stdev))
plt.bar(x, values, width=0.1)
plt.xlabel("result")
plt.ylabel("num")
plt.show()
野手用
# -*- coding: utf-8 -*-
import os, sys, csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 基礎設定
file_name = 'meisyo_b 20181217.csv'
# CSV読み込み
df = pd.read_csv(file_name, encoding='utf-8')
# Null値を把握
# print(df.isnull().sum())
# 基礎設定
team = pd.DataFrame(index=[], columns=[])
# 投手能力結合・削除
for i in ['sp', 'co', 'st', 'bb1n', 'bb2n', 'bb3n']:
# df['p_'+i] = df['p_'+i] + df['pt_p_'+i] + df['pw_p_'+i]
df = df.drop(['pt_p_'+i, 'pw_p_'+i], axis=1)
for i in ['bb1', 'bb2', 'bb3', 'bb0k', 'bb1k', 'bb2k', 'bb3k']:
df = df.drop(['p_'+i], axis=1)
# 野手能力結合・削除
for i in ['mt', 'pw', 'sp', 'sf', 'df', 'er', 'ss']:
df['b_'+i] = df['b_'+i] + df['pt_b_'+i] + df['pw_b_'+i]
# df = df.drop(['b_'+i, 'pt_b_'+i, 'pw_b_'+i], axis=1)
team = df
# 不必要品削除
df = df.drop(['mn_id', 'name', 'side_p', 'type', 'type_p', 'hp', 'cond', 'cond_b', 'img', 'exp', 'time', 'skill', 'game.1', 'id.1', 'g_bench', 'g_pos', 'g_sb', 'game', 'pc_type', 'bt_type', 'grow_type'], axis=1)
# 欠損値のある行を削除
df = df.dropna()
# 不必要分削除
df = df.drop(['type_b', 'side_b', 'lv'], axis=1)
df = df.drop(['b_er'], axis=1)
# データ確認
#print(df.isnull().sum())
# 結果データ作成
rs = pd.DataFrame(index=[], columns=[])
rs['id'] = df['id']
rs['ave'] = df['h'] / df['ab']
rs['obp'] = (df['h'] + df['bb'] + df['hbp']) / (df['ab'] + df['bb'] + df['hbp'] + df['sf'])
rs['slg'] = df['tb'] / df['ab']
rs['ops'] = rs['obp'] + rs['slg']
# 野手結果削除(結果に直接相関する)
df = df.drop(['pa', 'ab', 'h', 'risp_b', 'risp_h', '1b', '2b', '3b', 'hr', 'tb', 'rbi', 'rs', 'sh', 'sf', 'bb', 'hbp', 'so', 'dp', 'e_er', 'tc', 'm_er', 'sb', 'cb', 'c_sb', 'c_cs'], axis=1)
# データ欠損値の埋め合わせ
rs = rs.fillna(0)
# データ設定
x_col = df.drop('id', axis=1)
x = x_col.values
y_ave = rs.values[:, 1]
y_obp = rs.values[:, 2]
y_slg = rs.values[:, 3]
y_ops = rs.values[:, 4]
print(df.isnull().any())
print(rs.isnull().any())
#必要なパッケージのインポート
from sklearn import linear_model
model_ave = linear_model.LinearRegression()
model_obp = linear_model.LinearRegression()
model_slg = linear_model.LinearRegression()
model_ops = linear_model.LinearRegression()
# 学習する
model_ave.fit(x, y_ave)
model_obp.fit(x, y_obp)
model_slg.fit(x, y_slg)
model_ops.fit(x, y_ops)
# 偏回帰係数
print("ave")
print(pd.DataFrame({"Name":x_col.columns, "Coefficients":model_ave.coef_}).sort_values(by='Coefficients') )
print(model_ave.intercept_)
print("obp")
print(pd.DataFrame({"Name":x_col.columns, "Coefficients":model_obp.coef_}).sort_values(by='Coefficients') )
print(model_obp.intercept_)
print("slg")
print(pd.DataFrame({"Name":x_col.columns, "Coefficients":model_slg.coef_}).sort_values(by='Coefficients') )
print(model_slg.intercept_)
print("ops")
print(pd.DataFrame({"Name":x_col.columns, "Coefficients":model_ops.coef_}).sort_values(by='Coefficients') )
print(model_ops.intercept_)
# 結果表示
print(x_col.columns)
print(model_ops.coef_)
# 相関図
myteam = {}
for key, row in team.iterrows():
if row['mn_id'] == 'れい' and row['type'] == 'B':
sum = 0
for i in x_col.columns:
sum += row[i]
myteam[row['name']] = '{:.0f}'.format(sum);
for k, v in sorted(myteam.items(), key=lambda x: x[1]):
print(str(k) + ": " + str(v))
# stop
sys.exit()
# グラフ用
y_aveV = ['{:.2f}'.format(n) for n in y_ave]
y_obpV = ['{:.2f}'.format(n) for n in y_obp]
y_slgV = ['{:.2f}'.format(n) for n in y_slg]
y_opsV = ['{:.2f}'.format(n) for n in y_ops]
# plot
data = y_aveV
import collections
list = collections.Counter(data)
x = np.arange(100) / 100
values = []
for i in x:
i = '{:.2f}'.format(i)
print(str(i) + ":" + str(list[i]))
if list[i]:
values.append(list[i])
else:
values.append(0)
values[0]=0 # 0を無視
# 計算
from statistics import mean, median,variance,stdev
print(data)
data = [float(s) for s in data]
m = mean(data)
median = median(data)
variance = variance(data)
stdev = stdev(data)
print('平均: {0:.2f}'.format(m))
print('中央値: {0:.2f}'.format(median))
print('分散: {0:.2f}'.format(variance))
print('標準偏差: {0:.2f}'.format(stdev))
plt.bar(x, values, width=0.1)
plt.xlabel("result")
plt.ylabel("num")
plt.show()






[…] [Meisyo]ビッグデータから学ぶ試合の基礎設計4から早4か月。 「球速の上方修正してほしいな」というコメントが届きました。 […]